deepLabV3Plus는 이전 논문들과 다르게 모델 구조가 살짝 복잡합니다. 그래서 모델을 구현하는 것에 중점을 맞출 것입니다.
이전에 사용한 논문을 다시 가져왔습니다.

atros conv는 기존의 conv를 변형한 것입니다. tensorflow 에서는 DepthwiseConv2D에 dilation_rate 속성을 주어 구현할 수 있는데 귀찮으니 ResNet50을 그대로 가져다 쓰겠습니다.
모델 구현
우선 512,512,3 크기를 입력받는다고 하겠습니다. keras.applications에서 ResNet을 가져옵니다. weights는 초기 가중치, include_top은 마지막 dense 레이어를 포함하는지 여부, input_tensor은 입력 크기입니다.

저희 모델의 큰 그림은 아래와 같습니다.
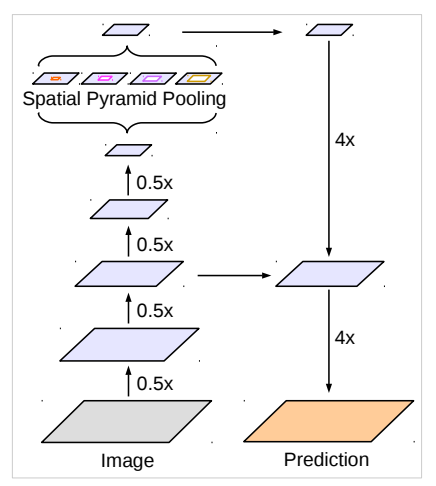
여기서 *0.5를 4번한 레이어를 conv4_block6_2_relu에서 가져올 것입니다.
그리고 어떻게 pyramid를 잘 했다고 칩니다.
그리고 이 레이어를 4배를 해줍니다. UpSampling2D에서 size라고 하지만 사실 몇 배 증가하느냐로 생각하면 됩니다. 변수명을 잘못 지은 거 같아요

그럼 저희는 아래 부분까지 완료했습니다.

디코딩 부분은 resnet의 출력 부분보다 4배 큰 곳에서 가져와야 합니다. 그러니 conv2_block3_2_relu에서 가져오도록 합시다.
1*1 conv를 하고 batchNorm과 ReLU까지 하면 위 그림에서 Concat 직전까지 완료됩니다.

이제 두 레이어를 하나로 합쳐준 뒤 Conv -> BatchNorm -> ReLu를 하고 크기를 원래대로 올려줍니다. 마지막으로 Conv 한번 더 하면 출력 부분까지 완성됩니다.

pyramid
이제 알아서 잘 하겠지 하고 넘어간 부분을 봅시다.
우선 입력 크기를 구합니다. AveragePooling -> conv -> batchNorm -> ReLU -> Upsampling을 해서 피라미드의 가장 하래 부분을 만들어 줍니다.

가장 위 부분은 kernal_size와 dilation_rate를 1로 주어서 만들 수 있습니다.

가운데 부분은 kernal_size=3, dilation_rate만 조절해서 만들어 줄 수 있습니다.

이제 이거를 하나로 합친 뒤 model_output을 리턴해 주면 됩니다.




