기본 규칙
영어를 한글로 바꾸는 것은 정말 어렵습니다. "rkqkd(가방)"이라는 글자가 있으면 'rk', 'qkd'으로 끊어줘야 합니다. 어디서부터 어디까지가 한 글자인지 알아야 한다는 것이죠. 우선 몇 가지 규칙을 찾아봤습니다.
- 모음은 항상 중성입니다.
- 초성이 없는 중성 뒤에 자음이 오면 이 자음은 항상 초성입니다.
- 모음 뒤에 모음이 올 수 있는 경우는 "ㅘ", "ㅙ", "ㅚ", "ㅝ", "ㅞ", "ㅟ", "ㅢ" 뿐입니다.
- 초성은 항상 자음 하나입니다.('ㄳ' 같은 경우는 없습니다.)
이 규칙을 고려했을 때 다음과 같은 방법을 생각해 볼 수 있습니다.
- 입력한 영어를 글자로 바꿉니다.
- 모음인 경우(1번 규칙)
- 앞글자가 없으면 "초성이 없는 중성"입니다.
- 앞글자도 모음이면 앞글자와 합쳐질 수 있는지 확인합니다(3번 규칙). 합칠 수 있으면 합치고 아니면 앞글자에서 끊은 후 "초성이 없는 중성"이 됩니다.
- 앞글자가 자음이면 받아 올림을 하듯 앞글자를 가져와 "초성이 있는 중성"이 됩니다. 그리고 그 앞에서 글자를 끊어줍니다.
- 자음인 경우
- 앞글자가 없으면 초성입니다.
- 앞글자가 모음인 경우 자신이 종성이 될 수 있는지 확인합니다. 될 수 있으면 종성이 되고 아니면 앞글자에서 끊은 후 초성이 됩니다.(2번 규칙도 고려합니다.)
- 앞글자가 자음인데 초성이면 앞글자에서 끊은 후 초성이 됩니다.(4번 규칙)
- 앞글자가 자음인데 종성이면 합쳐질 수 있는지 확인합니다. 합칠 수 있으면 합치고 아니면 앞글자에서 끊은 후 초성이 됩니다.(4번 규칙)
구현
이 규칙을 이제 구현해 보겠습니다.
조금 편하게 생각하기 위해서 한글을 바꾸는 경우와 영어를 바꾸는 경우로 나눠봅시다.
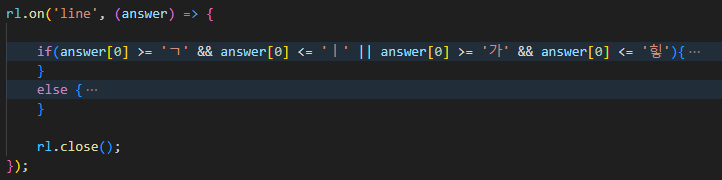
이제 모음인 경우와 자음인 경우로 나눠보겠습니다.

모음인 경우부터 먼저 처리해 보겠습니다. 여기서 word는 지금 보고 있는 한글에 해당하는 영어, change()는 그 영어를 한글로 출력하는 함수입니다.

이제 자음인 경우를 처리해 봅시다. 모음이 아니면서 알파벳이면 한글을 입력한 경우라고 생각하겠습니다.
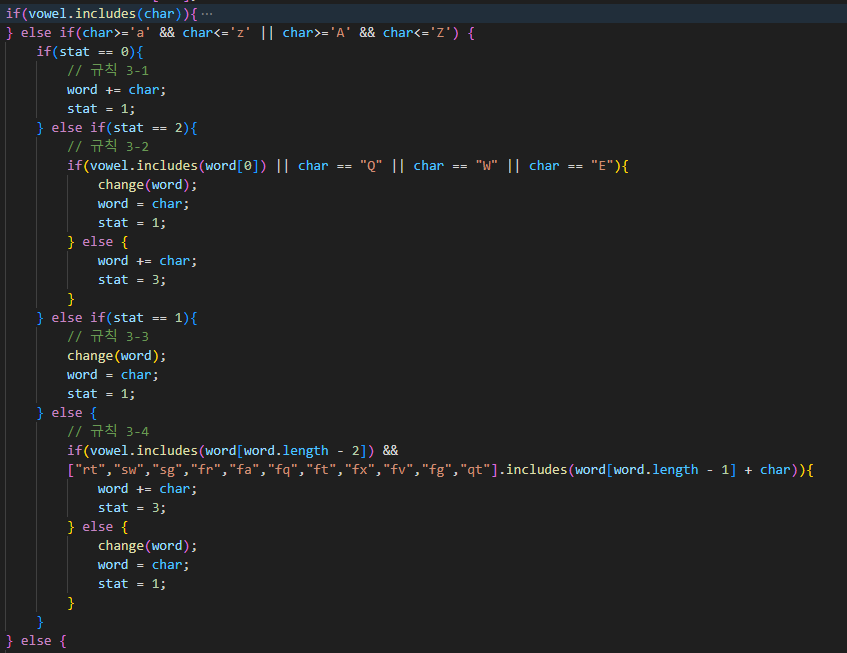
그 외의 경우(" ", ",", "?", "~")는 그 위치에서 글을 끊어주고 해당 문자도 출력해 줍니다.

이제 change를 구현해 줍니다. 우선 초성, 중성, 종성 별로 어떤 글자가 어떤 순서로 오는지 배열에 저장해 줍니다.

그리고 글자를 초성, 중성, 종성으로 끊어주고 해당 글자를 출력해 줍니다. curStat이 1이면 초성, 2면 중성, 3이면 종성을 보고 있다는 뜻입니다.

실행하면 다음과 같이 나옵니다.

코드
const readline = require('readline');
const rl = readline.createInterface({
input: process.stdin, // 터미널에서 입력
output: process.stdout, // 터미널에 출력
});
let ko = ["ㄱ","ㄲ","ㄳ","ㄴ","ㄵ","ㄶ","ㄷ","ㄸ","ㄹ","ㄺ","ㄻ","ㄼ","ㄽ","ㄾ","ㄿ","ㅀ","ㅁ","ㅂ","ㅃ","ㅄ","ㅅ","ㅆ","ㅇ","ㅈ","ㅉ","ㅊ","ㅋ","ㅌ","ㅍ","ㅎ","ㅏ","ㅐ","ㅑ","ㅒ","ㅓ","ㅔ","ㅕ","ㅖ","ㅗ","ㅘ","ㅙ","ㅚ","ㅛ","ㅜ","ㅝ","ㅞ","ㅟ","ㅠ","ㅡ","ㅢ","ㅣ"]
let en = ["r","R","rt","s","sw","sg","e","E","f","fr","fa","fq","ft","fx","fv","fg","a","q","Q","qt","t","T","d","w","W","c","z","x","v","g","k","o","i","O","j","p","u","P","h","hk","ho","hl","y","n","nj","np","nl","b","m","ml","l"]
let vowel = ["k","o","i","O","j","p","u","P","h","hk","ho","hl","y","n","nj","np","nl","b","m","ml","l"];
let first = ["ㄱ","ㄲ","ㄴ","ㄷ","ㄸ","ㄹ","ㅁ","ㅂ","ㅃ","ㅅ","ㅆ","ㅇ","ㅈ","ㅉ","ㅊ","ㅋ","ㅌ","ㅍ","ㅎ"]
let firstEn = ["r","R","s","e","E","f","a","q","Q","t","T","d","w","W","c","z","x","v","g"];
let second = ["ㅏ","ㅐ","ㅑ","ㅒ","ㅓ","ㅔ","ㅕ","ㅖ","ㅗ","ㅘ","ㅙ","ㅚ","ㅛ","ㅜ","ㅝ","ㅞ","ㅟ","ㅠ","ㅡ","ㅢ","ㅣ"]
let secondEn = ["k","o","i","O","j","p","u","P","h","hk","ho","hl","y","n","nj","np","nl","b","m","ml","l"];
let third=["","ㄱ","ㄲ","ㄳ","ㄴ","ㄵ","ㄶ","ㄷ","ㄹ","ㄺ","ㄻ","ㄼ","ㄽ","ㄾ","ㄿ","ㅀ","ㅁ","ㅂ","ㅄ","ㅅ","ㅆ","ㅇ","ㅈ","ㅊ","ㅋ","ㅌ","ㅍ","ㅎ"]
let thirdEn = ["","r","R","rt","s","sw","sg","e","f","fr","fa","fq","ft","fx","fv","fg","a","q","qt","t","T","d","w","c","z","x","v","g"];
function singleKoToEn(ko){
let uni = ko.charCodeAt(0) - 'ㄱ'.charCodeAt(0);
process.stdout.write(en[uni]);
}
function multiKoToEn(ko){
let uni = ko.charCodeAt(0) - '가'.charCodeAt(0);
singleKoToEn(first[Math.floor(uni/588)]);
singleKoToEn(second[Math.floor(uni%588/28)]);
if(uni%28==0) return;
singleKoToEn(third[Math.floor(uni%28)]);
}
function change(word){
if(word == "") return;
if(en.includes(word)){
process.stdout.write(ko[en.indexOf(word)]);
} else{
let firstChar = "";
let secondChar = "";
let thirdChar = "";
let curStat = 1;
for(char of word){
if(curStat == 1 && vowel.includes(char)) {
curStat = 2;
} else if(curStat==2 && !vowel.includes(char)) {
curStat = 3;
}
if(curStat == 1) firstChar += char;
else if(curStat == 2) secondChar += char;
else if(curStat == 3) thirdChar += char;
}
let unicode = '가'.charCodeAt(0) + firstEn.indexOf(firstChar) * 588 + secondEn.indexOf(secondChar) * 28 + thirdEn.indexOf(thirdChar)
process.stdout.write(String.fromCharCode(unicode));
}
}
rl.on('line', (answer) => {
if(answer[0] >= 'ㄱ' && answer[0] <= 'ㅣ' || answer[0] >= '가' && answer[0] <= '힣'){
for(char of answer){
if(char >= 'ㄱ' && char <= 'ㅣ'){
singleKoToEn(char)
}
else if(char >= '가' && char <= '힣'){
multiKoToEn(char)
} else {
process.stdout.write(char);
}
}
}
else {
let stat = 0;
let word = "";
for(let idx = 0; idx < answer.length; idx++){
const char = answer[idx];
if(vowel.includes(char)){
if(stat == 0) {
// 규칙 2-1
word += char;
} else if(stat==2) {
// 규칙 2-2
if(['hk','ho','hl','nj','np','nl','ml'].includes(answer[idx - 1] + char)) {
word += char;
} else {
change(word);
word = char;
}
} else {
// 규칙 2-3
change(word.slice(0,-1));
word = word[word.length - 1] + char;
}
stat = 2;
} else if(char>='a' && char<='z' || char>='A' && char<='Z') {
if(stat == 0){
// 규칙 3-1
word += char;
stat = 1;
} else if(stat == 2){
// 규칙 3-2
if(vowel.includes(word[0]) || char == "Q" || char == "W" || char == "E"){
change(word);
word = char;
stat = 1;
} else {
word += char;
stat = 3;
}
} else if(stat == 1){
// 규칙 3-3
change(word);
word = char;
stat = 1;
} else {
// 규칙 3-4
if(vowel.includes(word[word.length - 2]) &&
["rt","sw","sg","fr","fa","fq","ft","fx","fv","fg","qt"].includes(word[word.length - 1] + char)){
word += char;
stat = 3;
} else {
change(word);
word = char;
stat = 1;
}
}
} else {
change(word);
word = ""
stat = 0;
process.stdout.write(char);
}
}
change(word);
}
rl.close();
});
발전시킬 부분
크롬 확장 프로그램 중 구글 번역기가 있습니다. 영어 단어를 선택하면 번역을 보여주는 확장 프로그램입니다.


영어로 쓴 부분을 선택해 주었을 때 한글로 바꿔주면 사용하기 편할 것 같습니다. 확장 프로그램을 만드는 방법을 배우게 되면 이것을 제일 먼저 해 볼 생각입니다.
'프로젝트' 카테고리의 다른 글
| opencv - 프로젝트 2 - 3. 카드 인식 (0) | 2024.06.28 |
|---|---|
| opencv - 프로젝트 2 - 2. 카드 인식 (0) | 2024.06.19 |
| opencv - 프로젝트 2 - 1. 카드 인식 (0) | 2024.06.08 |
| opencv - 프로젝트 1 - 1. 얼굴 모자이크 (0) | 2024.06.02 |
| java script - 프로젝트 1 - 1. 영어 한글 변환기 (1) | 2024.05.12 |



