어떤 문자열(이하 text)에서 특정 문자열(이하 pattern)이 있는지 판단하는 문제가 있다 합시다(https://www.acmicpc.net/problem/1786). text의 길이를 $N$, pattern의 길이를 $M$이라 하면 단순 비교로 할 때 $O(NM)$의 시간이 걸립니다. 이를 $O(N+M)$으로 만들어 주는 것이 KMP(Knuth-Morris-Pratt Algorithm)입니다.
방법
단순 비교로 하면 $O(NM)$이 걸린다고 했었죠. KMP는 이 알고리즘에서 불필요한 과정을 제거했습니다.
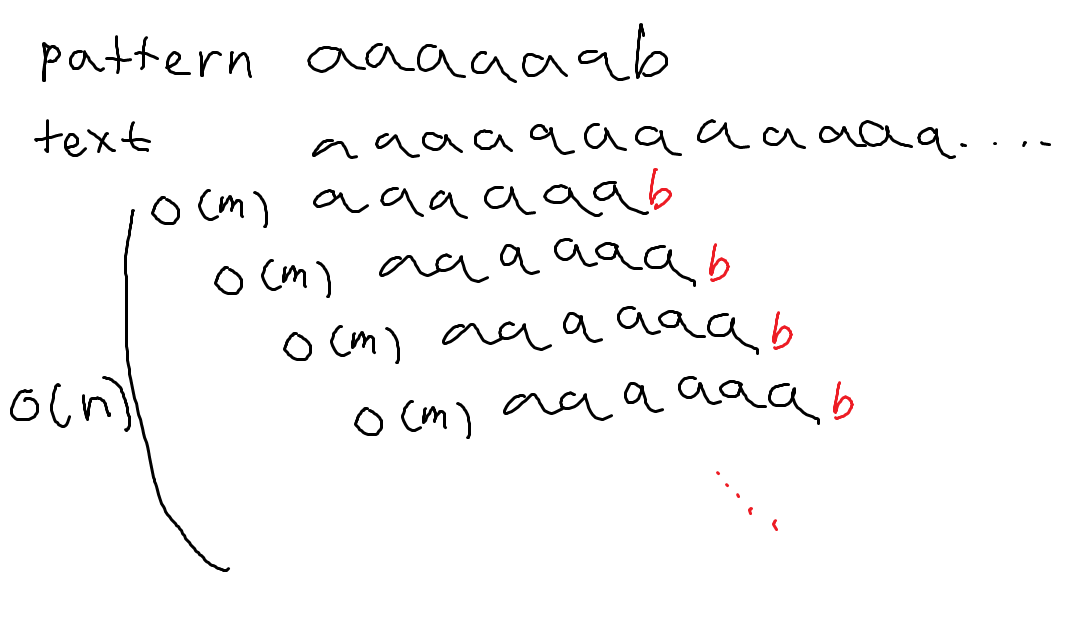
위 과정을 보면 aaaaaa 부분은 더이상 안봐도 될 것 같은데 계속해서 검사해 주고 있습니다. 이 부분을 줄이기 위해서는 fail function에 대해 알아야 합니다.
fail function
fail function(F)은 dp값이라고 생각하면 됩니다. 정확한 정의는 pattern의 각 위치에서 실패했을 때 다음 비교를 어디에서부터 해야 하는지 저장한 배열이지만, 이 글에서는
해당 위치까지의 부분 문자열이 갖는 접두사와 접미사가 일치하는 최대 길이
로 하겠습니다. 아래는 12131214와 aaaaaab의 F입니다. 각 pattern 밑에 있는 것이 F입니다.

F는 dp를 이용해 구할 수 있습니다. F[i-1]번째 값을 구했다고 해 봅시다. F[i]는 F[i-1] + 1 보다 클 수 없습니다(만약 F[i]=x라면 F[i-1]=x-1입니다). 만약 pattern[F[i-1]] = pattern[i]라면 F[i]는 F[i-1] + 1입니다.
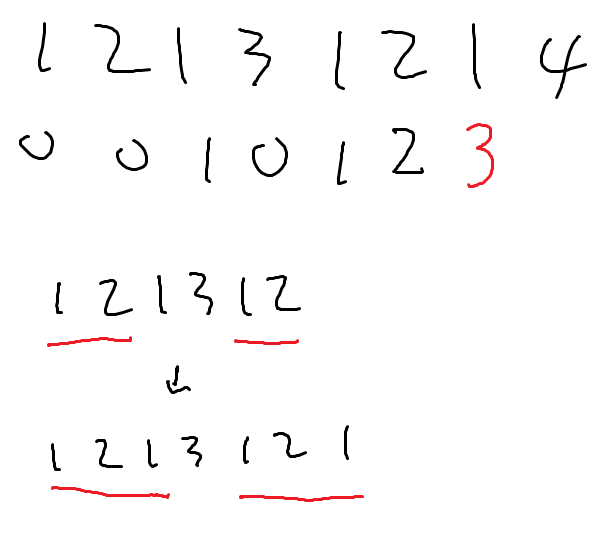
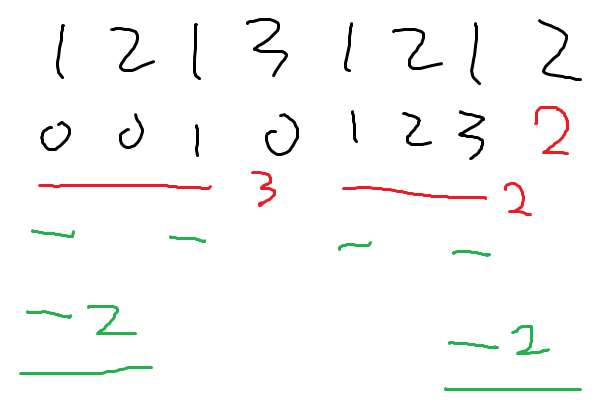
pattern[F[i-1]] != pattern[i]라고 해 봅시다. F[i-1]는 i-1에서 접두사와 접미사가 일치하는 최대 길이입니다. 그럼 두번째 길이는 얼마일까요? 바로 F[F[i-1]]입니다(정확히는 F[F[i-1]-1]). 세번째 길이는 F[F[F[i-1]]]이겠네요(정확히는 F[F[F[i-1]-1]-1]).
그럼 pattern[F[F[i-1]-1]] = pattern[i]면 F[F[i-1]-1]+1, pattern[ F[F[F[i-1]-1]-1] ] = pattern[i]면 F[F[F[i-1]-1]-1]+1, 이런 식으로 진행하면서 값을 채워주면 됩니다.
그래서 어떻게 하나요?
F는 구했는데 이것으로 어떻게 text와 일치하는 부분을 찾을 수 있을까요?
F의 원래 정의는 "실패했을 때 다음 비교를 어디에서부터 해야 하는지 저장한 배열"입니다. 매칭을 쭉 진행하다 중간에 틀렸다고 해봅시다.
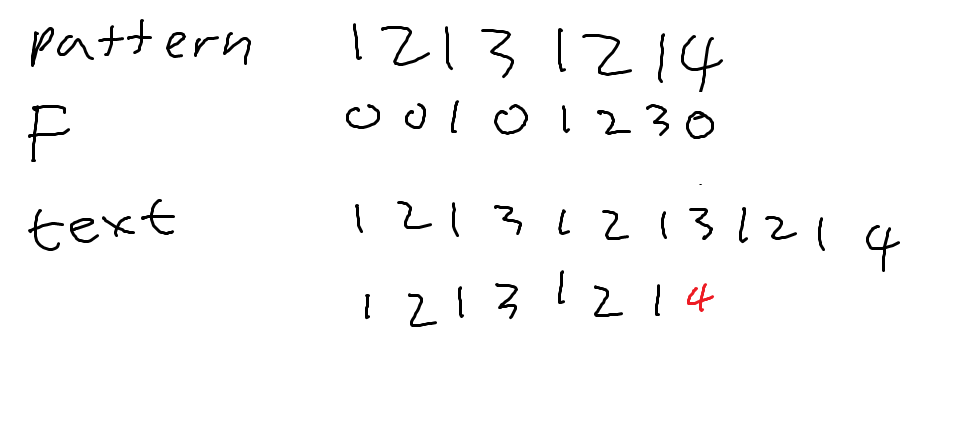
이때, 1213121의 F값은 3입니다. 즉, 처음부터 볼 필요 없이 3번째부터 진행해도 된다는 뜻입니다.
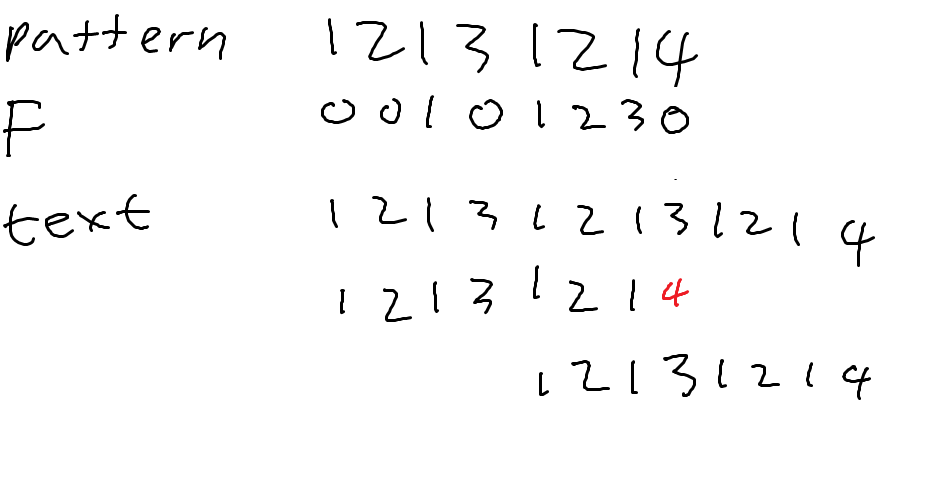
시간복잡도
현재 비교하고 있는 pattern의 위치를 $i$, text의 위치를 $j$라고 합시다. 만약 두개가 일치하면 $i$, $j$ 모두 1 증가합니다. 일치하지 않으면 $i$가 적어도 1 감소합니다. 즉, $O(N+M)$에 해결이 가능합니다.
KMP의 핵심은 F입니다. 접두사와 접미사가 일치한다는 것에 집중하면 이 글에서 빠트린 부분도 충분히 직접 유도할 수 있습니다. 이 글에 부족한 부분을 알려주시면 바로 보충하도록 하겠습니다.
'PS - 알고리즘' 카테고리의 다른 글
| 4544 - 'Roid Rage (0) | 2024.08.01 |
|---|---|
| 27933 - 대회 이름 정하기 (0) | 2024.07.25 |
| 6496 - Cyclic antimonotonic permutations (0) | 2024.07.18 |
| 16570 - 앞뒤가 맞는 수열 (0) | 2024.07.11 |
| 10523 - 직선 찾기 (0) | 2024.07.11 |


