MNIST 정도면 다른 곳에도 많겠지만 MNIST를 학습하는 과정을 적어보겠습니다.
MNIST는 손으로 쓴 숫자를 입력하면 어떤 숫자인지 맞춰주는 것입니다.
vscode를 이용해서 진행할 것입니다.
데이터 가져오기
tensorflow의 keras안에 mnist 데이터가 있습니다. 해당 데이터를 가져옵니다.

이 데이터는 정말 이쁘게 생겼습니다. train데이터와 test데이터가 이미 나누어져 있거든요. 데이터를 받고 크기를 출력해서 잘 받아왔는지 확인해 봅시다.

28*28 크기 이미지 60000개를 받아옵니다.
matplotlib.pyplot를 이용해 이미지를 출력할 수 있습니다. pip install matplotlib로 설치하고 다음 코드를 입력합니다.
plt.figure로 캔버스를 준비하고(근데 아마 이거 없어도 돌아가긴 할 겁니다.)
plt.imshow()로 그림을 그리고
plt.show()로 그림을 보여줍니다.(근데 아마 이거 없어도 돌아가긴 할 겁니다.)
label도 출력해서 값이 맞는지 확인해 줍니다.

이런 것을 할 때 타입을 신경 써줘야 합니다. dtype으로 타입을 확인해 봅시다.

음수가 없고 0~255 범위인 정수란 것을 알 수 있습니다.
근데 이론상 들어갈 수 있는 값의 범위가 이렇다는 거지 실제로 들어가 있는 값의 범위는 아닐 수 있습니다. 실제 값의 최대, 최소를 출력합니다. reshape(-1)로 전부 1차원으로 만들고 최대, 최소를 뽑아냅니다.

조금 더 자세히 보려면 pip install pandas로 pandas를 설치해 주고 dataframe의 describe로 자세히 확입합니다. images는 df로 넘기기 힘드니 labels만 확인해 봅시다.

pip install seaborn으로 seaborn을 설치하고 histplot으로 막대그래프를 그려봅니다.
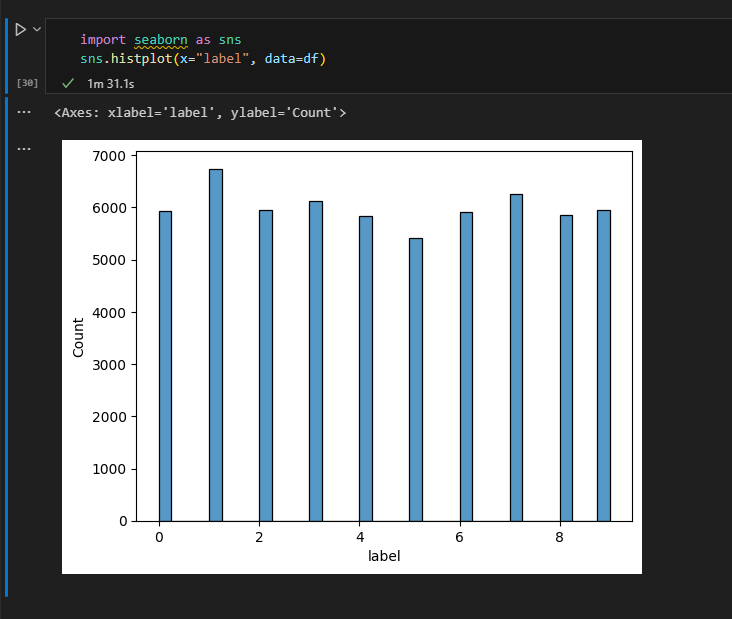
얼추 균등하게 있는 것 같습니다.
하지만 이미지 값의 범위기 0~255인 것이 마음에 들지 않네요. 값의 범위를 0~1로 바꿔보겠습니다.
astype으로 실수형으로 바꿔주고 255로 나눠줍니다.

이미지를 한눈에 보시 위해 5개를 출력했습니다.

transpose에 대해 잠시만 이야기하고 가겠습니다.transpose(x1,x2,x3)은
첫 번째 차원의 크기를 원래 차원의 x1번째 차원으로
두 번째 차원의 크기를 원래 차원의 x2번째 차원으로
세 번째 차원의 크기를 원래 차원의 x3번째 차원으로
바꾼다는 뜻입니다.

그럼 reshape()와 다른 것이 무엇이냐? reshape는 원소의 순서를 바꾸지 않고 transpose는 순서를 바꿉니다.
다음 배열을 생각해 봅시다.

1,2,3,4 그림,
5,6,7,8 그림,
9,10,11,12 그림입니다. shape는 (3,2,2)이겠네요. (개수, 가로, 세로)입니다.
[[[1,2],[3,4]] , [[5,6],[7,8]] , [[9,10],[11,12]]] 이렇게 저장되어 있습니다.
reshape는 순서를 바꾸지 않는다고 했죠. 만약 (2,3,2)로 reshape 한다면
[ [[1,2],[3,4],[5,6]], [[7,8],[9,10],[11,12]] ]
가 됩니다. 이전 정의대로라면 2개의 이미지, 3개의 가로줄, 2개의 세로줄이 됩니다.

transpose는 순서가 바뀌게 됩니다. 위 그림에 transpose(1,0,2)를 해봅시다.
첫 번째 차원은 원래 차원의 두 번째 차원입니다. 두번째 차원(가로) 기준으로 쪼개준 뒤 순서대로 붙여줍니다.

두번째 차원은 원래 차원의 첫 번째 차원입니다. 첫번째 차원(개수) 기준으로 쪼개준 뒤 순서대로 붙여줍니다.

세 번째 차원도 마찬가지로 하지만 바뀌는 것이 없으므로 넘어가겠습니다. 그럼 최종 배열은
[ [[1,2],[5,6],[9,10]], [[3,4],[7,8],[11,12]] ]
가 됩니다.
이 이후에 reshape(2,-1)을 하면 어떻게 될까요?
순서가 바뀌지 않으니

이런 모양이 됩니다. 이때부터 정의가 (개수, 가로, 세로)가 아닌 (가로, 세로)로 바뀝니다. 이 상태로 이미지를 보여주면 마치 세 이미지가 가로로 붙은 모양이 되죠.
data argumentation(데이터 가공)
이대로 학습하러 가도 되긴 하지만 너무 깔끔한 데이터로는 학습이 잘 안 될 수 있습니다. 정확히는 노이즈가 있는 데이터에 대해서는 판단을 잘 못할 수 있습니다. 그래서 데이터에 인위적으로 노이즈를 넣어주겠습니다.
np.random.random(크기)로 랜덤 한 값을 낼 수 있습니다.

(28*28) 크기의 랜덤 한 값을 만들었습니다. 랜덤 값은 0~1인 것 같네요.
조금 더 정확히 분포를 확인해 봅시다.

0~1 사이 값을 균등하게 만들어 주는 함수네요.
너무 균등한 건 마음에 들지 않습니다. 가우시안 분포로 노이즈를 만들어 줍니다.

이것 역시 분포를 확인해 봅시다.

아주 예쁜 가우시안 분포가 나오네요. 이 노이즈를 원본 이미지에 더해줍시다.

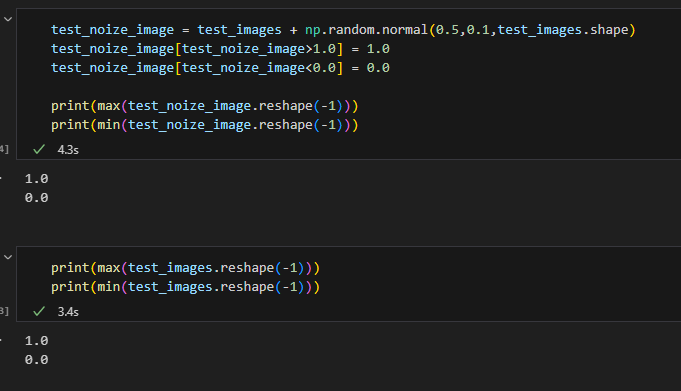
흠, 근데 max가 1을 넘고 min이 0보다 작은 값들이 분명 있을 것입니다. 이런 값들은 1,0으로 바꿔주도록 합니다.

test_image에도 똑같이 적용합니다.
이제 전처리를 모두 끝냈습니다. 다음 포스트에서 본격적으로 모델을 학습시켜 보겠습니다.
'개발 > 딥러닝' 카테고리의 다른 글
| [논문 구현] ImageNet Classification with Deep Convolutional Neural Networks (0) | 2024.05.22 |
|---|---|
| 1 - MNIST 모델 학습 (0) | 2024.05.19 |
| 인공지능 - 환경 세팅 오류 해결 (1) | 2024.05.18 |
| 인공지능 - 환경 세팅 (2) | 2024.05.17 |
| [논문 리뷰] ImageNet Classification with Deep Convolutional Neural Networks (0) | 2024.05.12 |



