이 전의 논문 리뷰에서는 모델의 구조에 집중을 했었습니다. 이 논문에서 딥러닝스러운 부분은 사실 cnn이 전부고 이미지를 전처리하는 데에 신경을 많이 쓰고 있습니다. 따라서 이 리뷰도 전처리에 신경을 쓰도록 하겠습니다.
무엇을 하는 녀석인가
각 객체들이 어디에 있는지 찾아주는 인공지능입니다.
개요
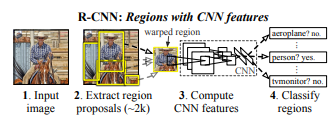
객체를 탐지하는데 크게 3 단계를 거칩니다.
- 각 이미지를 적절한 영역(2000개)로 나눕니다.
- 각 영역을 cnn에 넣습니다.
- 그렇게 나온 정보를 이용해서 어떤 객체인지 분류합니다.
적절한 영역을 어떻게 나누는가?
이 논문에서는 selective search 기법을 사용해서 구역을 나누었습니다. 헷갈릴 수 있으니 용어부터 잡고 진행합니다.
resion proposal : 객체가 있을 만한 곳을 찾는 것
selective search : resion proposal을 하는 기법 중 하나.
selective search는 다음 방법으로 이루어 집니다.
- 초기 이미지에서 비슷한 값을 가지고 있는 픽셀끼리 하나의 영역으로 묶어줍니다. 이때, 굉장히 많은 영역들이 생깁니다.
- 가장 유사도가 높은 두 영역을 하나로 묶어줍니다. 이때, 두 영역은 서로 접해있어야 합니다. 유사도는 색, 질감, 크기 등 여러 요소를 고려합니다.
- 영역이 2000개가 될 때 까지 반복합니다.
이제 각 영역들을 227*227크기로 변형해 줍니다(이 당시 cnn은 227*277만 입력으로 받을 수 있었습니다).
어떤 객체인지는 어떻게 구분하는가?
cnn을 사용했으니 그냥 Dense layer을 마지막에 두면 되겠지 싶었으나 이 논문에서는 Support Vector Machines(SVM)을 사용했습니다. SVM은 머신러닝 기법으로 어떤 벡터가 어떤 라벨에 포함되는지 판단해 줍니다.

영역이 2000개면 너무 많지 않나?
논문에 있는 이미지 하나를 가져 왔습니다.

논문에서는 background영역을 추가했습니다. 위 그림에서 1996개는 배경 영역에 해당하고 4개는 레몬 영역에 해당합니다. 배경은 보여주지 않았기 때문에 영역은 4개만 나와 있습니다.
이렇게 하면 또 다른 문제가 생깁니다. 특정 라벨이 너무 많으면 학습은 제대로 이루어 지지 않습니다. 지금 배경 영역이 너무 많기 때문에 이 문제를 해결하기 위해 훈련 시 의도적으로 배경이 아닌 영역을 더 많이 샘플링 했습니다.
라벨링은 어떻게?
각 영역의 중심 좌표(x,y)와 너비, 높이(w,h)를 이용해서 라벨링을 합니다. 그럼 사각형 하나(빨간색 사각형)가 나옵니다. 이렇게 하면 selective search를 했을 때 나오는 x,y,w,h랑을 차이가 날 것입니다(파란색 사각형). 그럼 아래의 파란색 사각형과 일치하는 라벨이 없으니 전부 배경으로 처리해야 할까요?

저희는 IOU를 이용해서 어떤 라벨에 포함될 지 판단합니다. IOU는 두 사각형이 있을 때 (두 사각형의 교집합의 넓이) / (두 사각형의 합집합의 넓이) 입니다.

만약 파란 사각형과 빨간 사각형의 IOU가 특정 값 이상이면 해당 레이블로 생각합니다.
정확한 영역은 어떻게 뽑지?
selective search에서 나온 값은 저희가 라벨링한 값과 위치가 정확히 일치하지 않습니다. 이 문제를 bounding box regression으로 해결합니다. selective search에서 나온 사각형의 위치를 조절해 줍니다.
저희가 예측한 사각형을 $P$, 거기에 대응하는 라벨링 된 사각형을 $G$라고 합시다. 저희는 $P$가 주어졌을 때 $G$를 예측하는 모델을 학습시킬 것입니다. 식으로 보면 $P$가 주어지면 $G$를 예측하는 $d$를 찾아야 합니다. 예측한 결과가 $\hat{G}$입니다.

먼저 $G$와 $P$가 얼마나 차이가 나는지를 계산합니다.

이 값을 이용해서 $w$를 계산합니다.

*은 x, y, w, h중 하나입니다. 그리고 $d$는 $\hat{w}^T_*\phi_5(P^i)$입니다. $ \phi_5(P^i) $는 $P$를 CNN을 통과해서 나온 feature vector입니다.
같은 영역이 여러 개 있으면?
selective search가 어떻게 되냐에 따라 다르지만 한 객체에 여러 개의 사각형이 있을 수 있습니다.(제일 위 카드)

학습을 할 때야 괜찮지만 사람이 볼 때는 너무 복잡해 보입니다. 이 경우 각 객체마다 하나의 예측만 있도록 만들어 줘야 합니다. 이것을 Non-max suppression 알고리즘으로 해결했습니다. 다음과 같은 방법으로 이루어 집니다.
- 상자마다 확신하는 정도(confidence score)를 측정하고 특정 수치 이하인 것들을 제거합니다.
- confidence score가 가장 높은 것에 대해서 그 사각형과 주변 사각형과의 IOU를 계산합니다.
- IOU가 높은 사각형을 제거합니다.
이렇게 하면 RCNN을 학습시킬 수 있습니다.



