Faster R-CNN에서는 학습하는 데에 여러 단계가 필요했습니다. 이 과정을 한 단계로 줄인 것이 SSD입니다.
모델이 상당히 간단한 녀석이기 때문에 실제로 구현한다고 생각하면서 구현에 필요한 정보 기준으로 말씀드리겠습니다.
기본 개념
R-CNN에서는 selective search, faster-rcnn에서는 resion proposal network와 anchor box를 통해 물체가 있을만한 곳을 살펴보았습니다. 근데 selective search는 뭔가 정확하지 않을 것 같고 anchor box는 크기가 너무 정해져 있어 큰 물체와 작은 물체가 함께 있으면 둘 다 인식하기 어렵습니다.
SSD에서는 같은 크기의 anchor box(논문에선 default box로 표현하는데 편의를 위해 anchor box로 쓰겠습니다.)를 쓰긴 하는데 다양한 크기의 피쳐에서 사용할 것입니다. 저희는 이미지 분류를 할 때 CNN을 이용해서 이미지의 크기를 줄여나갔고 다양한 크기의 피쳐들이 생깁니다. 그럼 224*224 피쳐에서 3*3 anchor box를 쓰면 작은 물체를 인식할 수 있고 5*5 피쳐에서 3*3 anchor box를 쓰면 큰 물체를 인식할 수 있을 것입니다.

SSD
우선 vgg-16을 통과시키다 19*19*1024 크기의 피쳐 맵에서 멈춥니다. 여기서 CNN을 계속 적용해 1*1*256까지 만듭니다. 이 과정에 있는 38*38*512(vgg 중간에 있는 피쳐), 19*19*1024, 10*10*512, 5*5*256, 3*3*256, 1*1*256 피쳐에서 정보를 뽑아줄 것입니다.
각 피쳐의 픽셀마다 anchor box를 적용해 줄 것입니다. 위에 있는 classifier 부분입니다. 3*3은 필터 크기, 4는 anchor box의 수, classes는 해당 클래스 일 확률, 4는 박스 위치 조정할 오프셋입니다. 아래는 38*38 피쳐 맵에서 나온 것이니 38*38*4개의 앵커박스가 만들어지고 각 앵커박스마다 각 클래스 별 확률 + 오프셋이 들어가 있습니다.

이 과정을 모두 거치면 8732개의 앵커박스가 생깁니다(5776+2166+600+150+36+4). 이제 이 박스들에 non-maximum suppression으로 박스를 적절히 없애주면 됩니다.
로스
분류에 대한 로스와 위치에 대한 로스를 합해주었습니다. conf는 분류, loc는 위치에 대한 로스입니다. alpha는 두 로스에 대한 비율을 다르게 적용하기 위한 것입니다. N은 저희가 예측한 상자입니다.
이 부분은 faster rcnn과 크게 다르기 않습니다. 위치에 대한 로스는 다음과 같이 계산됩니다.

pos는 ground truth와 많이 겹치는 상자들(양성)입니다. 저희가 예측한 상자 인덱스를 i, ground truth 인덱스를 j라고 하면 $x_{ij}^k$는 i와 j가 잘 맞으면 1, 아니면 0입니다. 어렵게 써져 있지만 잘 맞는 상자들에 대해서만 계산하겠다는 것입니다.
분류에 대한 로스는 다음과 같습니다.
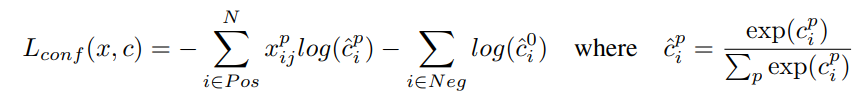
classification 로스로 구했습니다. 이건 특별할 게 없습니다.
anchor box
사실 위에서 "같은 크기의 anchor box"를 쓴다고 했는데 이거는 거짓말입니다. 저희는 6개의 피쳐맵에서 anchor box를 적용했는데 첫 번째 피쳐에서는 크기가 작고 마지막 피쳐에서는 크기가 큽니다. m을 피쳐 수(= 6)이라 할 때 다음 공식이 만들어집니다.

k번째 피쳐의 anchor box 크기는 원래 이미지를 $S_k$배 한 것입니다. 논문에서는 $S_{min}=0.2, S_{max}=0.9$를 사용했습니다. 그리고 다양한 비율의 anchor box를 사용했는데요, $\{1, 2, 3, 1/2, 1/3\}$, 그리고 비율 1에 조금 더 큰 anchorbox까지 6개를 사용했습니다.
저희는 각 피쳐의 픽셀마다 크기와 좌표를 구해 줬습니다. anchor box의 비율이 1이면 그대로, 2면 세로로 2배, 0.5면 가로로 2배로 크기를 조절해 줍니다.
Hard negative mining
이전 논문도 그렇고 저희는 ground truth와 IOU가 높으면 양성, 아니면 음성으로 판단했는데요, 이렇게 하면 음성 데이터가 너무 많아집니다. 이 상태에서 학습을 하면 학습이 잘 안되기 때문에 조금 걸러내야 하는데요, 이 논문에서는 음성 데이터 중 confidence 점수가 높은 데이터(음성인데 양성일 가능성이 높다고 하는 데이터들)만 학습에 사용했습니다.



